Welcome to the Aruna v3 Workshop
Overview
Agenda
Part 1: Learning & Discovery (1.5 hours)
v2 vs v3
We'll begin by examining the differences between Aruna versions 2 and 3, recapping v2, highlighting what has changed, and what new capabilities have been introduced. This comparison will provide context for understanding the evolution of Aruna evolved and help you identify migration considerations.
Feature Deep Dive
Following our comparative overview, we'll conduct a thorough exploration of version 3's feature set. Each capability will be presented with detailed descriptions, use cases, and practical applications. You'll learn not just what each feature does, but when and how to implement it effectively in your workflows.
Live Demonstration
Part 1 concludes with a comprehensive demonstration where we'll showcase the features in action.
Part 2: Hands-On Experience (1.5 hours)
Interactive testing
In our second session, you'll have direct access to a testing environment where you can experiment with version 3 features firsthand. This practical component allows you to explore and discover the functionalities at your own pace.
Q&A and Discussion
Throughout the hands-on portion, we will be available to answer questions, provide guidance, and help troubleshoot any challenges you encounter. This interactive format ensures you leave with confidence in using the new system.
Who are we?




What is Aruna
Federated
Eliminate the need for central coordination, avoid vendor lock-in, and get rid of single points of failure.
READ MORE >>FAIR
Locality aware, and FAIR compliant data orchestration across organizational boundaries.
READ MORE >>Sovereign
Easy collaboration while retaining authoritative control of local data and infrastructure.
READ MORE >>Part 1: Learning & Discovery (1.5 hours)
v2 vs v3
We'll begin by examining the fundamental differences between versions 2 and 3, highlighting what has changed, what has been enhanced, and what new capabilities have been introduced. This comparison will provide crucial context for understanding the evolution of our product and help you identify migration considerations.
Feature Deep Dive
Following our comparative overview, we'll conduct a thorough exploration of version 3's feature set. Each capability will be presented with detailed descriptions, use cases, and practical applications. You'll learn not just what each feature does, but when and how to implement it effectively in your workflows.
Live Demonstration
Part 1 concludes with a comprehensive demonstration where we'll showcase the features in action. This live demo will illustrate real-world implementation scenarios and demonstrate best practices for feature utilization.
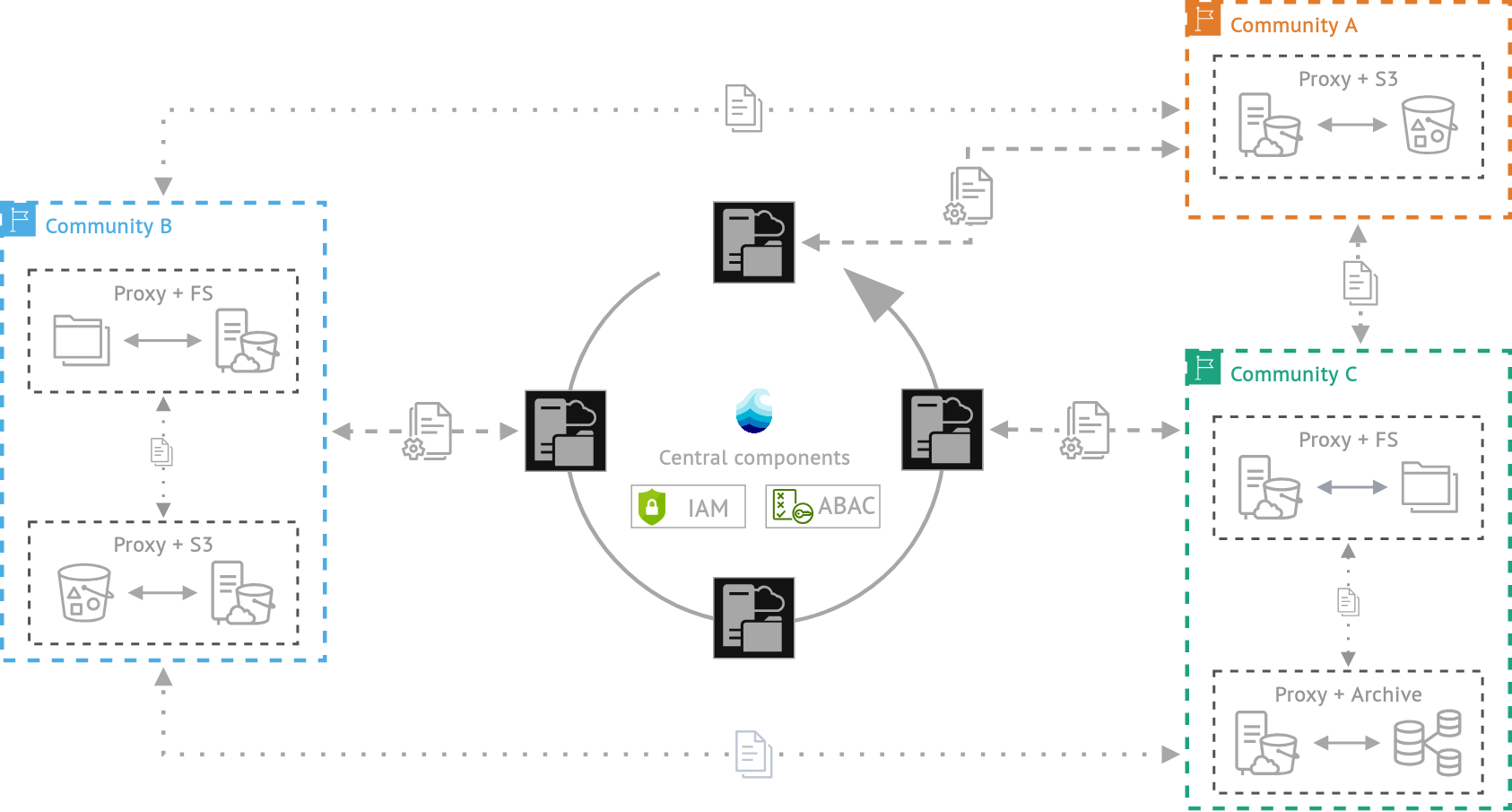
Aruna v2 Recap
More Info
The system architecture consists of multiple interconnected services that work together to deliver comprehensive data orchestration capabilities. Data distribution is managed centrally while maintaining FAIR compliance principles throughout the platform. Access control operates through an Attribute Based Access Control (ABAC) system, providing granular permission management. The core infrastructure includes Aruna Server instances for management operations, Aruna Dataproxy components for data handling, Nats for asynchronous messaging between instances, Yugabyte as the distributed database foundation, and Meilisearch for maintaining the public search index across registered resources. All Aruna Server instances share a single distributed relational database that ensures consensus for write operations, maintaining ACID compliance. The current implementation supports a limited hierarchical data organization model for structuring datasets and collections.
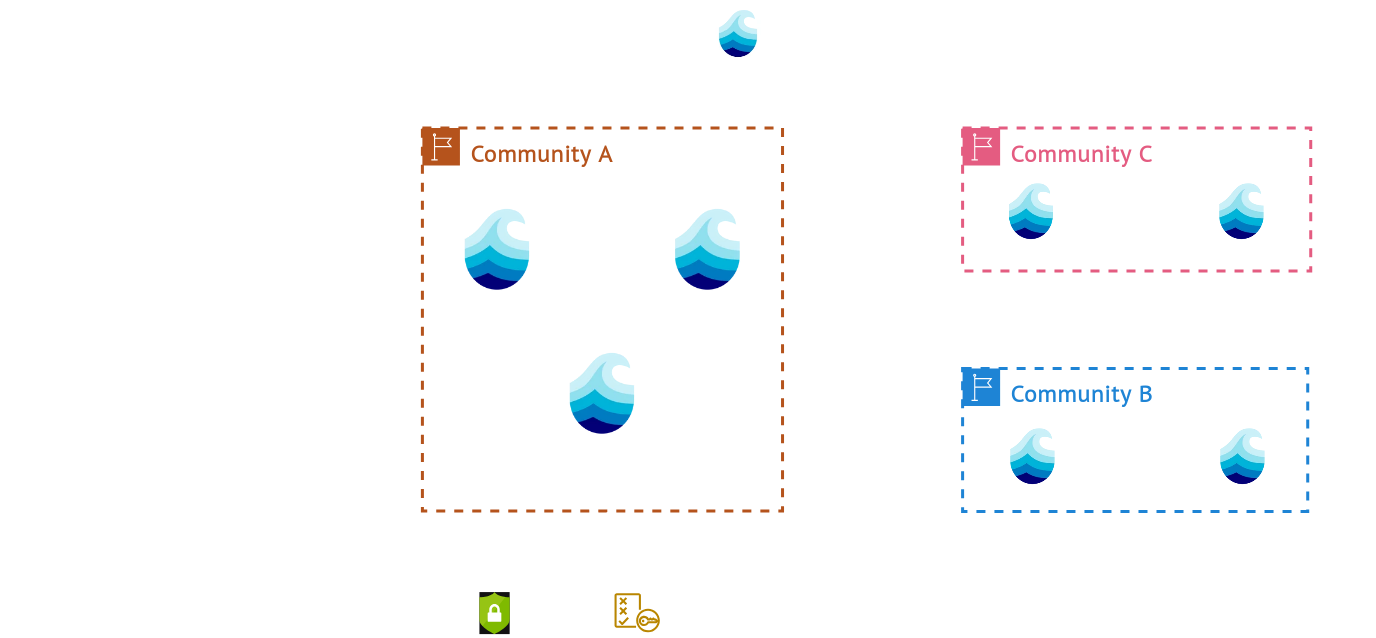
Aruna v3
More Info
These changes deliver significant operational and strategic advantages for research institutions and scientific communities. The federated architecture eliminates dependency on developer-maintained central infrastructure, enabling autonomous network operation and theoretically unlimited horizontal scaling as new nodes join the federation. Participants maintain complete sovereign control over their data and infrastructure while benefiting from network-wide collaboration capabilities. The simplified single-service deployment model reduces operational complexity compared to v2's multiple interconnected components, lowering technical barriers for institutional adoption. Additionally, the Realm-based compartmentalization allows scientific domains to establish independent governance structures within the broader network, fostering discipline-specific collaboration while maintaining interoperability across the entire Aruna ecosystem.
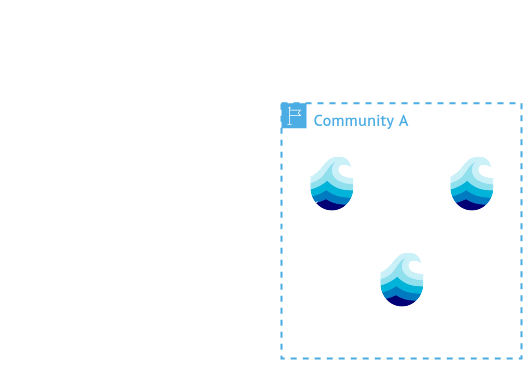
Nodes
- Are completely autonomous
- Act as primary access to:
- Storage Infrastructure
- Compute Cluster
- Single binary with config
- Individuals can also participate as Nodes
More info
In a federated scientific data management system, individual nodes serve as autonomous components that collectively form a distributed research infrastructure. Institutional Storage Gateway Nodes provide access to large-scale research repositories, exposing datasets while maintaining local security policies. Personal Research Nodes represent scientists' laptops or workstations that share specialized datasets, analysis tools, or computational resources directly from personal environments. Compute Cluster Gateway Nodes serve as entry points to high-performance computing resources, enabling remote access to parallel processing clusters or specialized facilities. Each node maintains its own security boundaries and governance while contributing to seamless cross-institutional resource and data sharing. A node can also perform several of these roles simultaneously, enabling advanced data orchestration strategies such as data-to-compute and compute-to-data in the network.
Node Communication
- P2P network
- DHT to make data/metadata available to the network
- CRDTs are used for collaborative metadata editing
- Data and Metadata can be shared and replicated with other Nodes
More info
Nodes are connected via a P2P network and are organized into realms that share the same set of policies. When data/metadata is registered at a node, it gets distributed via a DHT so every other node can associate a metadata/data entry with a node address. This guarantees a distributed system, where every resource is findable while still being managed and access-controlled by the original data holder. Nodes inside the same realm trust each other and can share resources by default with another (based on realm policies). Collaborative editing of metadata is made possible by CRDTs which asynchronously manage edits on metadata in our P2P system.
Realms
- A layer of trust between Nodes
- Nodes with same private key form a realm
- Can employ their own policies for data/metadata, etc.
- User Identity is always bound to a Realm
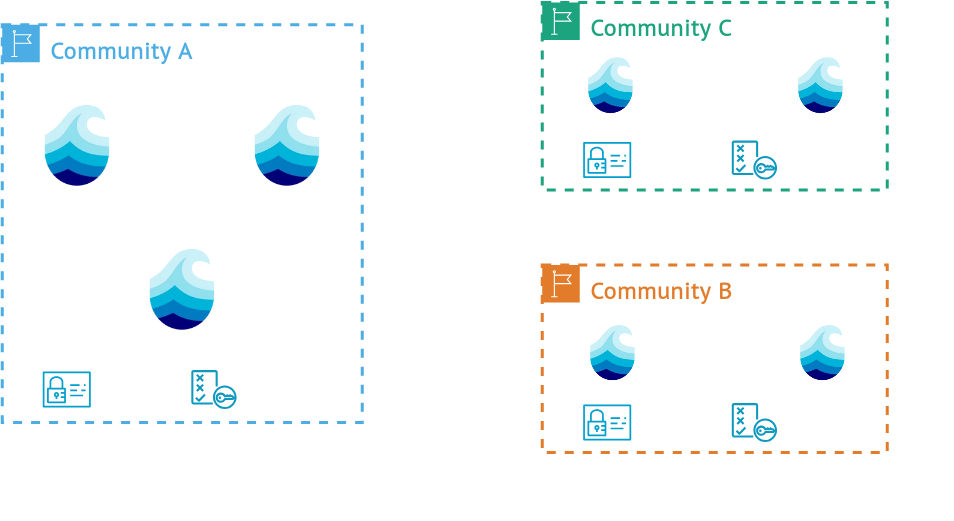
More info
Because realms share the same cryptographic key, nodes participating in realms trust each other. This ensures that a set of defined Nodes uses the same policies for authorization, authentication, metadata handling and data replication. By default access relevant information is shared with every other node in a realm. Data and metadata can be replicated by default to nodes inside a realm, while manual replication is still possibly with other nodes from other realms, but without the guarantee to use the same access restrictions. This flexible approach guarantees a resilient data storage system, where data and metadata can be dynamically transferred. Policies can for example, define how access should be managed, how data should be replicated, which metadata standards need to be enforced or which fields need to be set on metadata, so that consistent metadata handling is ensured in a realm. Users that are registered in a realm can interact with other realms via the identity provider used by their home-realm, supporting interoperability between nodes and realms.
Groups
- Form the basis of every auth-based action in a realm
- Organize users, resources and permissions
- Role-based permission handling
- Users can request access or can be added by group administrators

More info
Groups are used to organize users and permissions and form the basis of access-control and permission management for resources. Users can be part of one or multiple groups and are added by group admins or can request access to specific groups. Every user can get assigned to one or more roles that represent permissions. These permissions can be assigned for example to only permit individual resources or allow only metdata or data management. This allows for a flexible, fine-grained authorization system.
Metadata
- Metadata is stored as RO-Crate
- Base metadata standard: Schema.org
- Uses Dublin Core term `conformsTo`
- Collaborative work on metadata is handled by CRDTs
- Linked meta/data relations allow for scalibility, beyond conventional databases
- Detailed version history for every action on metadata
- Every metadata object is searchable via a distributed search index in each realm
- Authorized distributed search of metadata contents
More info
The basis of metadata is the json-based RO-Crate standard. This means that every metadata object must adhere to the schema.org standard. These standards enable more flexiblity on nearly every point compared to version 2.
This for example allows for:
- One metadata definition collecting multiple data entries
- One metadata definition collection other metadata definitions
- Distributed linked metadata
- inclusion of descriptions for non-aruna metadata links
Collaborative editing of metadata is handled by CRDTs, allow for flexible asynchronous merging of changing actions. Every change results in a new version that gets collected in a version history. Each change not only includes the resulting action, but also the user that triggered the change, the node that executed the change and the realm where the action took place in. Because metadata can now contain metadata that is located at other nodes or even realms, the distribution of metadata and data becomes easier than before. This not only allows for much higher scaliblity than version 2, allowing for example the integration of massive databases inside the p2p-aruna system, but also giving researchers the possibility to store data on a resilient federated system.
Data
- S3 compatible interface for easy up- and download
- Compatible with many storage backends through OpenDAL
- Currently FS, S3, FTP, Postgres
- Manual replication or configurable replication policies
- Easy ingestion of existing data per API
- Content hash addressable data resources
- Easy discovery of content because content hashes are stored in DHT
More info
Files can be uploaded independently of metadata creation via an s3 interface. Data can be located at nodes by its content hash, or by its s3 path. While s3 paths can change, content hashes cannot, allowing for pinning specific data versions via content hashes, while still allowing for flexiblity of paths via the s3 interface. Data can be stored in different data-backends, allowing for flexible deployment of nodes in vastly different environments. Not only newly created data can be stored on nodes, but also existing data on supported backends can be ingested to a node, allowing for data reuse and integration of existing data sources into aruna. Data can be replicated to other nodes via replication policies. Disclaimer: Filters in replication policies are currently ignored. If a complete bucket gets replicated, the associated paths and permissions are also replicated. If only some objects are replicated, they are only replicated by content hash, without their s3 paths. This means, that data can be accessed at any node by its content hashes, but only on some nodes by its s3 paths. Uploaded data can be linked to metadata objects, including their technical metadata. This allows for workflows to first create all neccessary data and load it into aruna, and then select only the neccessary data to be linked in one or more metadata objects.
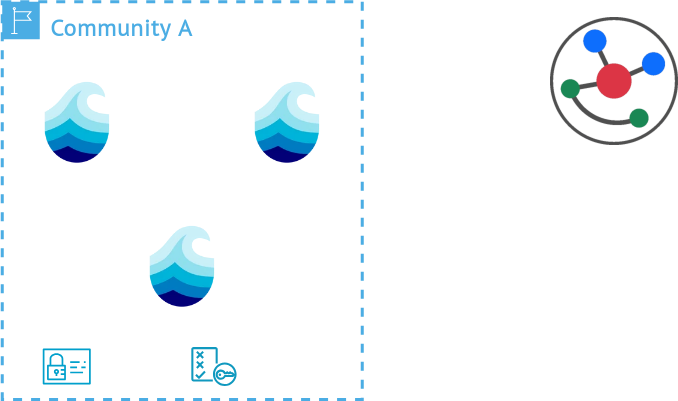
Policies
- Basic build blocks for the different layers of trust
- Define which actions are allowed on which resources
- Can be defined realm wide or node specific
- Are programmatically evaluated
More info
Policies form the basis of autonomy for each resource and node. They define what needs to be done or what is permitted on specific resources and can be integrated on a resource, group, node or realm level. These form the building block of the different layers of trust inside a p2p network. Because different institutions or consortia have different constraints, a defined set of policies is defined for each realm. This can include replication policies for data or metadata and policies that deny for example specific actions for specific nodes. The resulting flexiblity allows for example differentiation between higher-trust nodes, included in access-constrained compute environments that still can participate in a realm and the p2p network. Programmatic definition allows for maximum flexibility at the definition level and ensures that even complex scenarios are covered.
Hooks
- Interface to integrate external service
- TES compliant
- Triggers based on resource actions
- Associated with locality information
- Enriched with metadata context
More info
With hooks users can define actions that can trigger task execution of external TES services. Within the p2p network, specific nodes can be associated with specific compute resources, that can automatically trigger workflow executions. This powerful integration can efficiently route workflow jobs to the nearest compute resource to allow for data-to-compute patterns. Each job can be enriched with metadata information coming from the triggering resource action, helping to not only enrich metadata and data with provencance information, but also helping workflows to carry metadata information to external services.
Client interface (UI)
- One client cross-compiled for all devices
- Realm-wide websites as an interface to all nodes
- Local UI for temporary, local nodes
- CLI tool to work with remote as well as local instances
- ...
- Provides convenience functionality
More info
Similar to Arunas version 2, a website is planned to lower the entry barrier for participants in the p2p network. Each realm can also deploy custom services individually, which interacts with the API on behalf of the user, creating streamlined convenient interface to interact with realms. A local UI system is planned, similar to dropbox or torrenting managers, that help individual researchers to momentarily participate in the p2p network, to for example synchronize resources changes with remote nodes or share files with other individual researchers temporarily. To adress scripting and workflow execution, a CLI tool will be developed to help automate and script interactions with the p2p system.
Demo
This section demonstrates how to interact with the API using practical command-line examples.
Explore the endpoints below to learn how to easily communicate with any Aruna node.
Info Endpoint
Get general info about a specific Node
Use this endpoint to retrieve basic information about the requested node, including the Realm it belongs too, its id and network addresses.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8081/api/v3/info'
Response
{
"realm_id": "b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900",
"node_id": "a16395bd7963f6c618fadb266e0f5f52b98cbeacade7cf80449c6ce42c61d7d1",
"node_addr": {
"node_id": "a16395bd7963f6c618fadb266e0f5f52b98cbeacade7cf80449c6ce42c61d7d1",
"relay_url": null,
"direct_addresses": [
"134.176.138.7:1231",
"172.17.0.1:1231",
"172.18.0.1:1231"
]
}
}
Get general info about a specific Realm
Use this endpoint to retrieve basic information about the requested Realm.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>/api/v3/info/realm'
Response
{
"nodes": [
{
"realm_id": "b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900",
"node_id": "8e5c2c3e4771f91e7af9dd70a48cee50cb67070c3bef6ed9fcad821c85874b0f",
"node_addr": {
"node_id": "8e5c2c3e4771f91e7af9dd70a48cee50cb67070c3bef6ed9fcad821c85874b0f",
"relay_url": null,
"direct_addresses": [
"134.176.138.7:1230",
"172.17.0.1:1230",
"172.18.0.1:1230"
]
}
},
{
"realm_id": "b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900",
"node_id": "a16395bd7963f6c618fadb266e0f5f52b98cbeacade7cf80449c6ce42c61d7d1",
"node_addr": {
"node_id": "a16395bd7963f6c618fadb266e0f5f52b98cbeacade7cf80449c6ce42c61d7d1",
"relay_url": null,
"direct_addresses": [
"134.176.138.7:1231",
"172.17.0.1:1231",
"172.18.0.1:1231"
]
}
},
{
"realm_id": "b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900",
"node_id": "d3d0a9d61994ca137542b7267e95bf5a00cc0b6d51170f5b2c3c8adbfcbd5a0f",
"node_addr": {
"node_id": "d3d0a9d61994ca137542b7267e95bf5a00cc0b6d51170f5b2c3c8adbfcbd5a0f",
"relay_url": null,
"direct_addresses": [
"134.176.138.7:1232",
"172.17.0.1:1232",
"172.18.0.1:1232"
]
}
}
]
}
Search for resources by keyword(s)
Use this endpoint to search with keywords for metadata resources
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X 'GET' 'http://<node-host>:8081/api/v3/info/search?query=ecoli'
Response
{
"resources": [
{
"id": "string",
"name": "string",
"description": "string",
"revision": 9007199254740991,
"authors": [
{
"id": "string",
"first": "string",
"last": "string"
}
],
"content_len": 9007199254740991,
"count": 9007199254740991,
"created_at": "2025-09-19T10:24:53.193Z",
"data": [
{
"ContentHash": {
"datahash": "string"
}
},
{
"Link": "string"
}
],
"deleted": true,
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
"last_modified": "2025-09-19T10:24:53.193Z",
"license_id": "string",
"locked": true,
"title": "string",
"variant": "Project",
"visibility": "Public"
}
]
}
Users Endpoint
Add a new user
A new user needs to register via this endpoint. This returns a token, that can be used on any endpoint on the p2p network.
Request
curl -d '
{
"name": "Jannis Schlegel"
}' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X POST 'http://<node-host>:8081/api/v3/users'
Response
{
"token": "<your-initial-secret-token>",
"user": {
"id": "01K5EDZ8W7HRME69TM9SZ76YNB@b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900",
"name": "Jannis Schlegel",
"realm_key": [
1073741824
]
}
}
Query a user
A user can be queried via this endpoint. In the future this endpoint can be used by group admins to query information about any group members or users with public information.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8083/api/v3/users?id={user-identity}'
Response
{
"realm_id": "b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900",
"user_id": "01K5EDZ8W7HRME69TM9SZ76YNB@b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900>",
"user_name": "Jannis Schlegel"
}
Groups Endpoint
Create a new Group
This endpoint can be used to create a new group. Groups form the basis of authorization and authentication for resources in aruna.
Request
curl -d '
{
"name": "my_group"
}' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X POST 'http://<node-host>:8081/api/v3/groups'
Response
{
"group": {
"id": "01K60DD03CHA6ZZ3T01NDDPXN0",
"realm_key": [180, 230, 49, ...],
"name": "my_group",
"roles": [
"admin",
"member"
],
"members": {
"01K60DC77A5YCZH1Q2SKX73C3M@b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900": [
"admin"
]
}
}
}
Get info of a Group
Group information can be queried on this endpoint.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8081/api/v3/groups?id=01K60DD03CHA6ZZ3T01NDDPXN0'
Response
{
"group": {
"id": "01K60DD03CHA6ZZ3T01NDDPXN0",
"realm_key": [180, 230, 49, ...],
"name": "my_group",
"roles": [
"admin",
"member"
],
"members": {
"01K60DC77A5YCZH1Q2SKX73C3M@b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900": [
"admin"
]
}
}
}
Add User to a Group
Users can be added via AddUserRequests by group admins.
Request
curl -d '
{
"group_id": "01K60DD03CHA6ZZ3T01NDDPXN0",
"user_roles": {
"member": [
"01K60DQTQSSW6CT7V6254XR91P@b4e63113c8f2d85f743841abecd8b10a873aa43207306d86c212967c9a8c1900"
]
}' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-H 'Content-Type: application/json' \
-X POST 'http://<node-host>:8081/api/v3/groups/user'
Response
{}
Resources Endpoint
Create a new metadata project
A metadata project is the root ro-crate for a metadata collection. There is no need to create nested resources, because multiple datasets cann be added and annotated in one single metadata resource. Nesting is still possible to further structure your metadata or to scale things up if metadata gets large.
Request
curl -X 'POST' 'http://<node-host>:8081/api/v3/resources/project' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-H 'Content-Type: application/json' \
-d '
{
"authors": [
{
"first": "string",
"id": "string",
"last": "string"
}
],
"description": "string",
"group_id": "string",
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
"license_id": "string",
"name": "string",
"title": "string",
"visibility": "Public"
}'
Response
{
"resource": {
"id": "string",
"name": "string",
"title": "string",
"description": "string",
"revision": 0,
"variant": "Project",
"visibility": "Public",
"content_len": 123456,
"count": 0,
"created_at": "2025-09-29T06:47:25.047Z",
"last_modified": "2025-09-29T06:47:25.047Z",
"license_id": "string",
"locked": false,
"deleted": false,
"authors": [
{
"id": "string",
"first": "string",
"last": "string"
}
],
"data": [
{
"ContentHash": {
"datahash": "string"
}
},
{
"Link": "string"
}
],
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
}
}
Create a new metadata resource
Nested metadata resources can be appended to already existing metadata projects.
Request
curl -d '
{
"authors": [
{
"id": "string",
"first": "string",
"last": "string"
}
],
"description": "string",
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
"license_id": "string",
"name": "string",
"parent_id": "string",
"title": "string",
"variant": "Folder",
"visibility": "Public"
}' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X POST 'http://<node-host>:8081/api/v3/resources'
Response
{
"resource": {
"id": "string",
"name": "string",
"title": "string",
"description": "string",
"revision": 0,
"variant": "Project",
"visibility": "Public",
"content_len": 123456,
"count": 0,
"created_at": "2025-09-29T06:47:25.047Z",
"last_modified": "2025-09-29T06:47:25.047Z",
"license_id": "string",
"locked": false,
"deleted": false,
"authors": [
{
"id": "string",
"first": "string",
"last": "string"
}
],
"data": [
{
"ContentHash": {
"datahash": "string"
}
},
{
"Link": "string"
}
],
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
}
}
Get info of an existing metadata resource
Any metadata object can be queried from any node with a simple get request and the resource id.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8081/api/v3/resources?id=01K6AA6D7G48GNYMFD8G03QPWP'
Response
{
"resource": {
"id": "string",
"name": "string",
"title": "string",
"description": "string",
"revision": 0,
"variant": "Project",
"visibility": "Public",
"content_len": 123456,
"count": 0,
"created_at": "2025-09-29T06:47:25.047Z",
"last_modified": "2025-09-29T06:47:25.047Z",
"license_id": "string",
"locked": false,
"deleted": false,
"authors": [
{
"id": "string",
"first": "string",
"last": "string"
}
],
"data": [
{
"ContentHash": {
"datahash": "string"
}
},
{
"Link": "string"
}
],
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
}
}
Get change history of a metadata resource
The change history of every action that was called on a specific resource can be displayed with a query in the history endpoint.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8081/api/v3/resources/history?id=01K6AA6D7G48GNYMFD8G03QPWP'
Response
{
"history": [
{
"actor_id": {
"node_id": "string",
"realm_key": "string",
"user_identity": "string"
},
"deps": [
"string"
],
"extra_bytes": [
1073741824
],
"hash": "string",
"message": "string",
"operations": [
"string"
],
"seq": 10,
"start_op": 9007199254740991,
"time": 9007199254740991
}
]
}
Update title of a metadata resource
Metadata fields are currently updated with a specfic endpoint for each field. This will change over time to allow for more flexible json-based metadata edits
Request
curl -d '
{
"id": "01K6AA6D7G48GNYMFD8G03QPWP",
"title": "Some new title"
}' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X POST 'http://<node-host>:8081/api/v3/resources/title'
Response
{
"resource": {
"id": "01K6AA6D7G48GNYMFD8G03QPWP",
"name": "string",
"title": "Some new title",
"description": "string",
"revision": 0,
"variant": "Project",
"visibility": "Public",
"content_len": 123456,
"count": 0,
"created_at": "2025-09-29T06:47:25.047Z",
"last_modified": "2025-09-29T06:47:25.047Z",
"license_id": "string",
"locked": false,
"deleted": false,
"authors": [
{
"id": "string",
"first": "string",
"last": "string"
}
],
"data": [
{
"ContentHash": {
"datahash": "string"
}
},
{
"Link": "string"
}
],
"identifiers": [
"string"
],
"labels": [
{
"key": "string",
"value": "string"
}
],
}
}
Create s3 credentials
S3 Credentials for a user are always group specific. They can be created for any node in the registered realm.
Request
curl -d '
{
"group_id": "string"
}' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X POST 'http://<node-host>:8080/api/v3/users/credentials'
Response
{
"access_key_id": "<your-access-key-id>",
"secret_access_key": "<your-secret-access-key>""
}
Get S3 credentials
Your already created credentials can always be displayed with a `GetCredentialsRequest`. Credentials are only valid for each individual node.
Request
curl -H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8080/api/v3/users/credentials'
Response
{
"access_key_id": "<your-access-key-id>",
"secret_access_key": "<your-secret-access-key>""
}
Deleting S3 credentials
Credentials can be deleted on nodes with a `DeleteCredentialsRequest`.
Request
curl -H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X DELETE 'http://<node-host>:8080/api/v3/users/credentials' \
Response
{}
Get data locations
Existing data locations can be queried by their respective content-hashes. In a flexible p2p system like aruna this is especially useful to automate actions based on resource locality.
Request
curl -H 'accept: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X GET 'http://<node-host>:8080/api/v3/data/location?hash=ebae78bcd5a3ef259a4da35b3ac39ea29b8e147eb288c69404dd1bfa58280df4'
Response
{
"location": [
{
"direct_addresses": [
"0.0.0.0:1230"
],
"node_id": "",
"relay_url": "null"
}
]
}
Register data from storage backend
Existing data sources you have access to can be registered via this endpoint. This currelntly only works for individual objects, but gets further extended in the future.
Request
curl -d '
{
"backend_path": "/some-path/to/the/data.log",
"bucket": "my_bucket",
"create_s3_path": true,
"group_id": "01K60DD03CHA6ZZ3T01NDDPXN0",
"key": "<some-s3-key-id>"
}' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-secret-token>' \
-X POST http://<node-host>:8080/api/v3/users/credentials'
Response
{
"access_key_id": "<some-ulid>>",
"secret_access_key": "<some-secret-key>"
}
S3 Endpoint
To interact with the s3 endpoint you need a s3 client. Our recommendation for this demo is the official aws cli. Other clients should work, but are not tested and most of them are not feature complete.
Creating s3 buckets
A bucket can be created without any other restriction other than having valid S3 credentials
Request
aws --endpoint-url http://<node-s3-endpoint> \
--profile <aws-credentials-profile> \
--no-verify-ssl \
s3 mb s3://<your-bucket-name>
Response
make_bucket: <your-bucket-name>
Data uploads
Data uploads (single and multipart) are done with the s3 put convenience function.
Request
aws --endpoint-url http://<node-s3-endpoint> \
--profile <aws-credentials-profile> \
--no-verify-ssl \
s3 cp <your-local-object> s3://<your-bucket-name>/<your-remote-name>
Response
upload: ./<your-local-object> to s3://<your-bucket-name>/<your-remote-name>
Data downloads
Data can be downloaded the same way data is uploaded.
Request
aws --endpoint-url http://<node-s3-endpoint> \
--profile <aws-credentials-profile> \
--no-verify-ssl \
s3 cp s3://<your-bucket-name>/<your-remote-name> <your-local-object>
Response
download: ./<your-local-object> to s3://<your-bucket-name>/<your-remote-name>
Data replication
Data can be replicated to other nodes via the put-bucket-replication interface of s3.
Request
aws --endpoint-url http://<node-s3-endpoint> \
--profile <aws-credentials-profile> \
--no-verify-ssl \
s3api put-bucket-replication \
--bucket <your-bucket-name> \
--replication-configuration '
{
"Role": "arn:aws:s3:::",
"Rules": [
{
"ID": <your-replication-rule-name>,
"Destination": {
"Bucket": "arn:aws:s3:<target-node-id>:account_id:<target-bucket>"
},
"Status": "Enabled"
}
]
}'
Response
{}
Querying replication rules
Data replication rules can be viewed with this request.
Request
aws --endpoint-url http://<node-s3-endpoint> \
--profile <aws-credentials-profile> \
--no-verify-ssl \
s3api get-bucket-replication \
--bucket <your-bucket-name>
Response
{
"ReplicationConfiguration": {
"Role": <your-user-id>,
"Rules": [
{
"Status": "ENABLED",
"ExistingObjectReplication": {
"Status": "false"
},
"Destination": {
"Bucket": <your-bucket-name>
}
}
]
}
}
Welcome to the Aruna v3 Workshop
Overview
This exclusive preview workshop combines structured learning with early access testing, ensuring you gain both theoretical understanding of upcoming changes and practical experience with pre-release features. Whether you're currently using version 2 or planning to implement our product for the first time, you'll develop advanced knowledge that will give you a significant advantage when version 3 officially launches.
We're excited to share this sneak peek with you and gather your insights to help shape the featureset draft.
Objectives
By the end of this workshop, you will have a clear understanding of the key improvements from version 2 to version 3, basic knowledge of all new features, and hands-on experience using these in real-world scenarios.
Part 1: Learning & Discovery (1.5 hours)
v2 vs v3
We'll begin by examining the fundamental differences between versions 2 and 3, highlighting what has changed, what has been enhanced, and what new capabilities have been introduced. This comparison will provide crucial context for understanding the evolution of our product and help you identify migration considerations.
Feature Deep Dive
Following our comparative overview, we'll conduct a thorough exploration of version 3's feature set. Each capability will be presented with detailed descriptions, use cases, and practical applications. You'll learn not just what each feature does, but when and how to implement it effectively in your workflows.
Live Demonstration
Part 1 concludes with a comprehensive demonstration where we'll showcase the features in action. This live demo will illustrate real-world implementation scenarios and demonstrate best practices for feature utilization.
Part 2: Hands-On Experience (1.5 hours)
Interactive testing
In our second session, you'll have direct access to a testing environment where you can experiment with version 3 features firsthand. This practical component allows you to explore functionalities at your own pace and discover how they apply to your specific needs.
Q&A and Discussion
Throughout the hands-on portion, our expert facilitators will be available to answer questions, provide guidance, and help troubleshoot any challenges you encounter. This interactive format ensures you leave with confidence in using the new system.
What should I test?
Here are a few suggestions for what you can try out and experience in the hands-on part of the workshop.
In any case, if you want to interact with or join the workshop cluster, you should join the OpenWrt network. Wwe have set it up especially for this workshop and in which the cluster/realm we have provided is also accessible.
Experiment with a local cluster on your laptop
This needs internet connection and [docker|podman] compose installed as you will download all needed containers to set up locally on your computer an Aruna cluster with 3 instances.
You'll find the Docker Compose file here. Just download it and run docker compose -f /path/to/the/compose.yaml up to explore the Aruna ecosystem via the
Swagger UIs of the spawned nodes.
This compose file spawns the following containers:
- A Keycloak which provides authentication
- A Minio which is used as ephemeral backend storage
- 3 Aruna instances whose API endpoints are available under the following links after started:
- Metadata: http://localhost:8080 / Data: http://localhost:8081 / S3: http://localhost:1337
- Metadata: http://localhost:8082 / Data: http://localhost:8083 / S3: http://localhost:1338
- Metadata: http://localhost:8084 / Data: http://localhost:8085 / S3: http://localhost:1339
For initial login to get a valid token you have to visit the website http://localhost:3000 and use one of the following usersarunaadmin:arunadminorregular:regular.
After login you immediately receive an OIDC token. This can be used to authorize yourself in one of the Swagger UIs to start your journey.
The first step should be to create a Group. Since you created the group, you automatically receive admin rights for it. This means you are free to add additional users to this group, upload data, etc. as you wish. Feel free to explore the API documentation and test other requests.
Hint: S3 credentials have to be created for each node individually!
Join the workshop Realm as User and distribute data
After joining the workshop network OpenWrt you can register yourself at http://192.168.1.210:3000 with any user data you like.
After registering, you will immediately receive your OIDC token. You can use this to authorize yourself in the Swagger UI of a node in order to register your user in the realm as a first step.
In the API response to the user's registration in Aruna, you will receive an Aruna token that can be used for authorization in the same way, but is valid for a longer period of time.
From here on you can create your own Group or ask others that they will add your user to their already existing Group to collaborate together.
Feel free to explore the API documentation and test other requests.
The dummy cluster contains the following accessible endpoints:
- A Keycloak which provides authentication: http://192.168.1.210:3000
- 4 Aruna instances whose API endpoints are available under the following links:
- Metadata: http://192.168.1.210:8080 / Data: http://192.168.1.210:8081 / S3: http://192.168.1.210:1337
- Metadata: http://192.168.1.174:8082 / Data: http://192.168.1.174:8083 / S3: http://192.168.1.174:1338
- Metadata: http://192.168.1.178:8082 / Data: http://192.168.1.178:8083 / S3: http://192.168.1.178:1338
- Metadata: http://192.168.1.148:8082 / Data: http://192.168.1.148:8083 / S3: http://192.168.1.148:1338
Hint: S3 credentials have to be created for each node individually!