Aruna v2 Recap
More Info
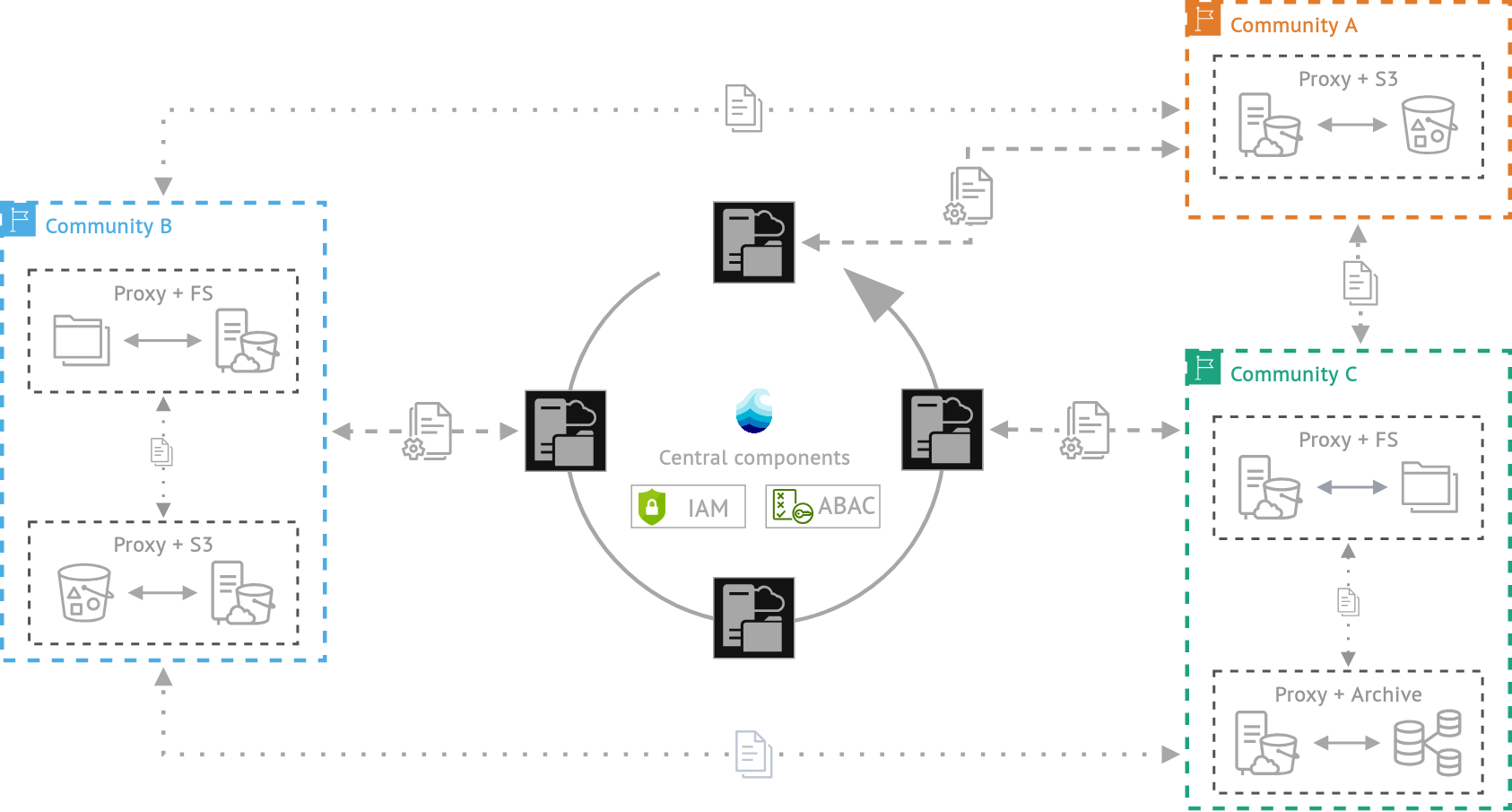
The system architecture consists of multiple interconnected services that work together to deliver comprehensive data orchestration capabilities. Data distribution is managed centrally while maintaining FAIR compliance principles throughout the platform. Access control operates through an Attribute Based Access Control (ABAC) system, providing granular permission management. The core infrastructure includes Aruna Server instances for management operations, Aruna Dataproxy components for data handling, Nats for asynchronous messaging between instances, Yugabyte as the distributed database foundation, and Meilisearch for maintaining the public search index across registered resources. All Aruna Server instances share a single distributed relational database that ensures consensus for write operations, maintaining ACID compliance. The current implementation supports a limited hierarchical data organization model for structuring datasets and collections.